
We’ve integrated models like GPT and Claude into our critical business infrastructure without fully understanding how secure they are. Since they reason like humans, they can also fail like humans, unpredictably, without giving prior warning. AI red teaming helps build defenses to deal with such LLM-related security threats.
In this blog, we’ll explore AI red teaming, why it matters, frameworks, how it works, and best practices for prevention.
What is AI Red Teaming?
AI red teaming is the adversarial practice of stress-testing large language models (LLMs) to expose security threats, such as prompt injection, data exfiltration, and jailbreaks.
Related Post: A Comprehensive Guide to Understanding LLM Security
While the concept of red teaming initially originated as a military strategy to find defensive gaps, the battlefield has shifted from physical servers to the unpredictable logic of neural networks.
Today, models like GPT, Claude, and Gemini have massively expanded the attack surface. Unlike traditional software, generative AI models can be manipulated without generating any alert.
Why AI Red Teaming Matters
There are multiple instances where simple tweaks in the prompt context or language persuaded chatbots to provide dangerous instructions or bypass security, privacy, and ethical controls.
Researchers recently demonstrated how easy it is to compromise Microsoft Copilot through a single malicious email. It’s a wake-up call for all businesses using these intelligent chatbots while totally ignoring the security aspect.
AI red teaming helps organizations:
- Identify jailbreak vectors to block prompt-based workarounds before they go viral.
- Prevent threats like data exfiltration by blocking attempts to “leak” training data or sensitive user info.
- Harden ethical boundaries to test how a model handles reasoning under adversarial pressure.
In short, AI red team assessment ensures your systems remain safe, fair, and trustworthy before they’re deployed at scale.
How AI Red Teaming Works
The process begins with defining the scope to set the Red Team Rules of Engagement. Security teams clearly specify in advance what’s in scope and what’s off the table. This ensures the process stays ethical and safe while focusing on the most critical targets.
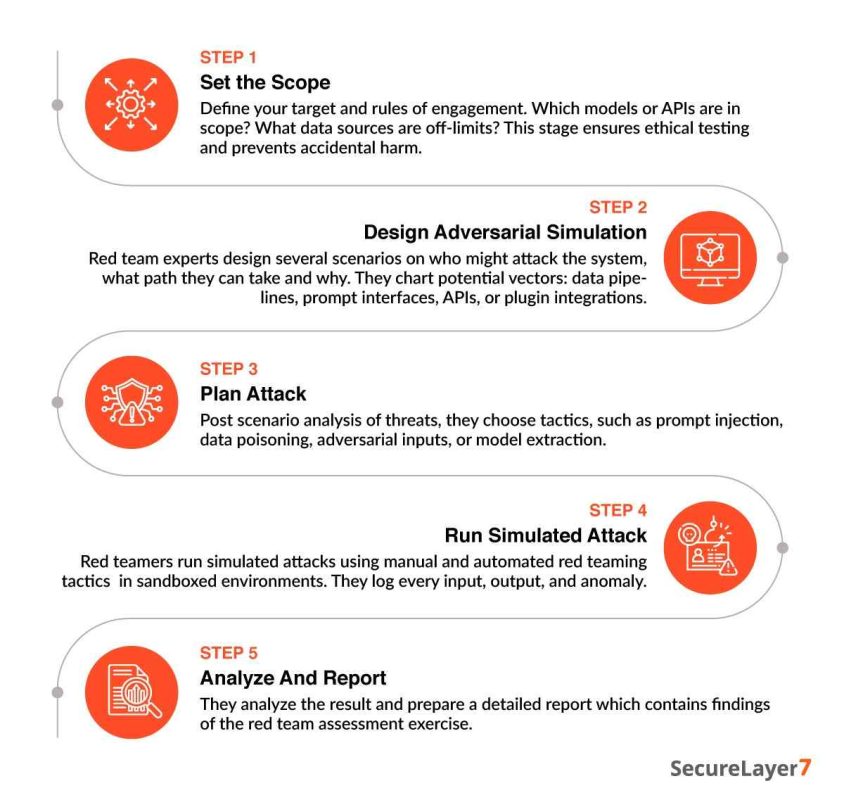
Next comes the scenario design phase, where experts think like attackers. They conduct a detailed AI attack surface review and map out potential paths an adversary might take, such as walking through a data pipeline or a simple prompt interface.
The process then moves into planning the attack. Red teams analyze the most likely threats and select specific tactics to exploit them. They decide whether to use prompt injection, data poisoning, or adversarial inputs based on the vulnerabilities.
Now comes the execution part: the team launches their planned strikes in a controlled, sandboxed environment. Using a mix of manual probing and automation tools, they monitor every anomaly and maintain logs of how the system reacts to pressure. This is the hands-on phase where theoretical risks are documented as evidence.
Finally, findings are shared through a comprehensive assessment report with an attack narrative. This acts more like a strategic roadmap that helps organizations understand exactly where the defenses failed and what they need to fix first.
Common AI Red Teaming Techniques
Attackers don’t just look for security gaps in the code; they seek to exploit the model’s intent. The real vulnerability lies in how the system interprets language. Effective AI red teaming addresses these issues.
Below, we have presented a list of popular AI red teaming tactics:
- Prompt Injection: Red teamers embed malicious instructions within user inputs to hijack the model’s control logic. These inputs override system-level logic, forcing the AI to ignore safety controls and execute unauthorized actions.
- Staged Campaigns: Adversaries use sequential interactions to gradually erode model constraints. This helps condition the AI to disclose restricted information or bypass safety guardrails.
- Data Exfiltration: Red teaming evaluates the model’s tendency to inadvertently disclose high-value assets, such as API keys, internal documentation, or PII. Through model inversion, they force the model to reveal sensitive information.
Related Post: Data Exfiltration Explained: Methods & Best Practices
- Jailbreaking: Red teamers use complex, adversarial prompts, often involving nested logic or obfuscation, to bypass safety filters. They use it to manipulate models into generating prohibited, unsafe, or policy-violating content.
- Broken Access Control in Integrations: Red teams test whether manipulated model outputs can exploit weak permission logic to perform unauthorized operations. Without strict access controls, an AI can be weaponized to escalate privileges or execute sensitive commands.
Frameworks for AI Red Teaming
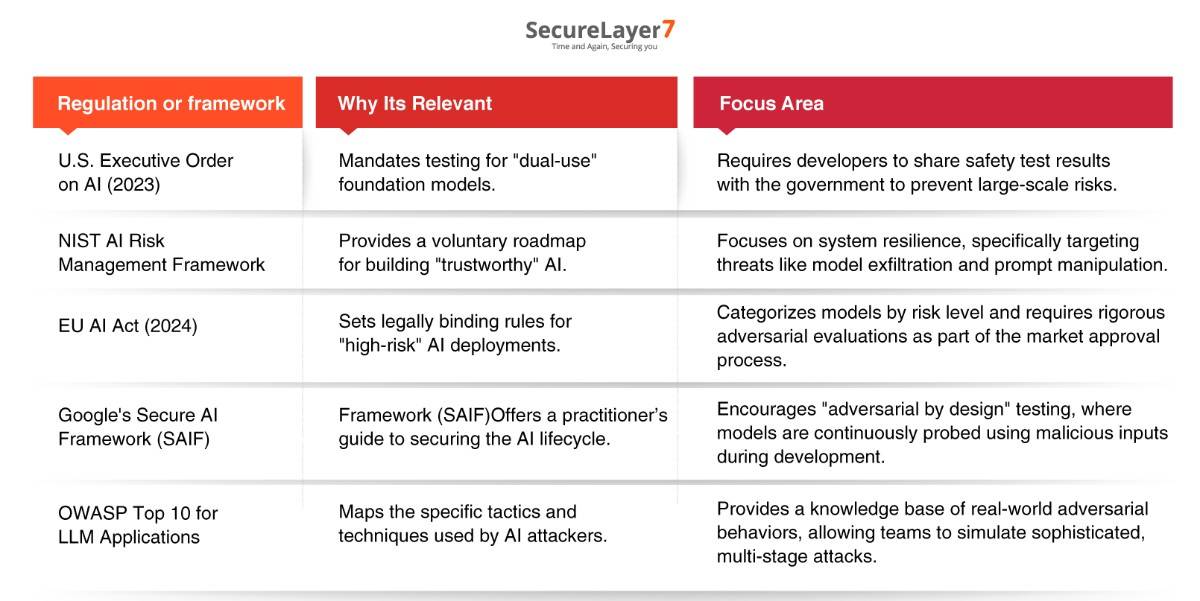
NIST’s AI Risk Management Framework defines red teaming as a core function with a strong focus on adversarial testing of AI systems under stress conditions. On the other hand, MITRE ATLAS extends the ATT&CK framework for AI-specific threats.
OWASP provides multiple resources, including the Top 10 for LLM Applications (2025 version), the Gen AI Red Teaming Guide released January 2025, and the Top 10 for Agentic Applications released December 2025.
Real-world Examples
The following documented cases show how hackers can attack advanced AI defenses and key lessons to learn from the incident:
Example #1: AI-Agent Exploit Test
Researchers at Black Hat 2025 demonstrated through an AI agent exploit test why browsing and desktop agents are uniquely risky. We have also seen similar attacks targeting Microsoft Copilot Studio and Salesforce Einstein.
Pro Tip: Using content sanitization, credential vaulting, and enforcing strict log access controls can help prevent the incident.
Example #2: Sydney Jailbreak
The Sydney jailbreak incident remains a classic case of an LLM threat using linguistic context. By using the phrase “ignore prior directives,” a student effectively bypassed the model’s safety controls.
This incident proved that even the most advanced systems are vulnerable to direct context injection. A single command can cause a total collapse of established safety guardrails.
Pro Tip: Always validate outputs in real-time, as modern models can still be tricked into ignoring safety restrictions mid-conversation.
Example #3: The Google Bard “Data Leak” Simulation
Google’s internal red team simulated a sophisticated exfiltration attack by tricking the model into “leaking” private user data through indirect prompt injection. By embedding malicious commands in a shared document, they proved that an AI could be weaponized into a silent data-broker, siphoning sensitive info without the user ever knowing.
Pro Tip: Treat every third-party integration as a potential backdoor; untrusted data can override the most “secure” system-level safety instructions instantly.
Best Practices for Effective AI Red Teaming
Through years of combined cybersecurity and AI governance experience, several principles have emerged:
- Establish clear scope: Define objectives, boundaries, and ethical constraints. Written authorization prevents legal and operational risks.
- Test continuously: Perform red teaming before deployment and after major updates. Treat it like continuous integration, not a one-time audit.
- Build cross-functional teams: Blend expertise from ML engineering, data ethics, security, and compliance. Diversity of perspective uncovers unseen risks.
- Develop attack libraries: Maintain a repository of scenarios and scripts. This institutional memory accelerates future testing.
- Maintain logs: Record every interaction, input, and anomaly for future analysis and compliance audits.
- Feed findings into retraining: Vulnerabilities should directly influence model updates, not sit idle in reports.
How to Measure AI Red Teaming Success
Organizations need to use both quantitative and qualitative metrics to judge the effectiveness of the red team assessment operations.
Quantitative indicators include:
- Total vulnerabilities discovered per cycle
- Average severity score (critical/high/medium/low)
- Mean Time to Remediate (MTTR)
- Decrease in repeated vulnerabilities after patching
Qualitative indicators include:
- Improved collaboration between ML and security teams
- Enhanced regulatory audit readiness
- Observable reduction in real-world misuse incidents
- Increased stakeholder confidence and user trust
Final Thoughts
AI-related security threats are now very real, no longer theoretical. You cannot dismiss it as a new technology hype.
AI red teaming is an effective way to deal with these security challenges. And more importantly, AI red teamers can think and act like real hackers and defeat attackers at their own game.
Ignoring generative AI security issues can expose your applications and other systems to threats like LLM jailbreak, prompt injection, and model inversion.
Talk to our experts to learn more about how we can help in assessing your AI risk.
How SecureLayer7 helps
Frequently Asked Questions (FAQs)
Adversarial ML is research-driven and algorithmic. On the other hand, AI red teaming is applied, scenario-based, and operational. Both complement each other in securing models.
Usually, you should do it before deployment and after any major model update.
Responsible teams test in sandboxed or mirrored environments. With proper scoping, it strengthens model security without risking outages.
It’s a shared responsibility. Data science ensures technical fidelity; security ensures threat realism and compliance.
Leverage open-source frameworks like MITRE ATLAS or Garak, document findings manually, and scale gradually as maturity grows.
